| Talk to Me |
 |
| APAO: 03 |
| Los sistemas con reconocimiento de habla |
Los sistemas de APAO mÃs avanzados tecnolµgicamente incorporan mµdulos de reconocimiento automÃtico del habla (RAH).
La aplicaciµn de esta tecnologÚa persigue dos objetivos fundamentales:
Los sistemas de APAO con estas prestaciones tecnolµgicas profundizan en el factor del feedback necesario en el proceso de aprendizaje, y son especialmente indicados para los contextos de autoaprendizaje.
La aplicaciµn del RAH (cuyo funcionamiento bÃsico se da por supuesto) en los sistemas de APAO genera dos particularidades: podrÚa decirse que una de ellas es negativa y otra positiva.
En primer lugar, las producciones que deben reconocerse no son "normales", sino propias de una interlengua. AdemÃs, esa interlengua varÚa en funciµn de las distintas L1 y de los diferentes estadios de aprendizaje de los alumnos.
Por tanto, los corpus de entrenamiento de estos sistemas deben ser especÚficos y pertencer a la interlengua para la que se pretenda aplicar el producto final.
A pesar de esa primera dificultad (mÃs bien especificidad), el reconocimiento en estos sistemas es mucho mÃs simple, porque los enunciados producidos son casi siempre controlados: el alumno debe reproducir el modelo qe se le ha propuesto.
Por tanto, el sistema no se centra en reconocer el enunciado (ya lo conoce), sino en la alineaciµn de la seþal del modelo y la del estudiante, y tambiÕn con el texto del enunciado corespondiente (en caracteres alfabÕticos o fonÕticos).
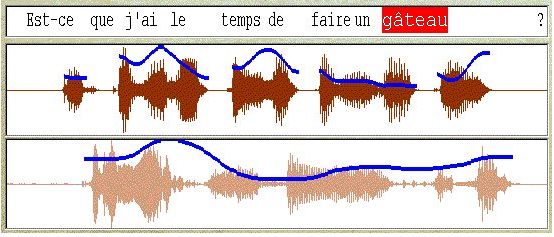
Este alineamiento no resulta fÃcil en la prÃctica, como puede imaginarse con este ejemplo de Talk to Me (tomado de CAZADE, 1999).
| Talk to Me |
|
Un primer aspecto que debe considerarse es el tecnolµgico, puesto que las tÕcnicas de reconocimiento aºn deben ser mejoradas. Pero Õsta es una tarea para ingenieros e informÃticos.
La primera cuestiµn que debe abordar la fonÕtica es la relacionada con el corpus de entrenamiento del sistema. Tampoco es el momento de discutir cuÃles son las caracterÚsticas tÕcnicas mÃs convenientes para un corpus de estas caracterÚsticas, sino de dejar claro que es el conocimiento fonÕtico el que debe dirigir su diseþo general.
Un producto muy interesante en este aspecto es el Speech Accent Archive desarrollado en la George Mason University, que presenta un mismo pÃrrafo pronunciado por un gran nºmero de hablantes de distintas lenguas. La web presenta una ficha completa de cada informante, la transcripciµn fonÕtica de cada producciµn y un sencillo resumen de sus particularidades fonÕticas mÃs relevantes.
| ACTIVIDAD |
| Obtenr informaciµn sobre corpus orales especÚficos para el Ãmbito APAO. |
| Algunas sugerencias: la web de ELRA; el proyecto ISLE, el proyecto ARNEFE; los corpus FRIDA, ELFA, JPU, TELC, Voice; los trabajos de MENZEL ET AL. (2000), GRANGER (2993)... |
| Discutir en comºn acerca de la informaciµn recogida. |
BONAVENTURA-HERRON-MENZEL (2000) proponen un mµdulo de detecciµn automÃtica de errores basado en reglas. Estas reglas deben recoger los principales errores de pronunciaciµn esperables en funciµn de la L1. De esta manera, se orienta al sistema a reconocer determinados fenµmenos, y se facilita ademÃs la tarea de proporcionar al usuario algunas explicaciones acerca de su error.
Los factores que inciden en la formulaciµn de las reglas son mºltiples:
Otros trabajos interesantes, pero que exceden tal vez el propµsito de estos apuntes, son TRUONG ET AL. (2004) y TRUONG ET AL. (2005).
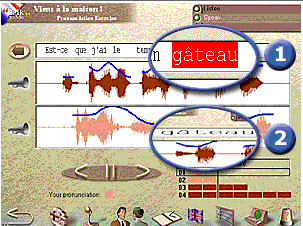
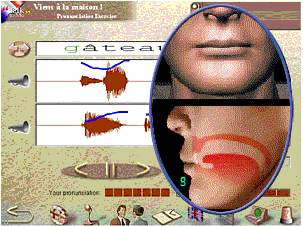
| Talk to Me French |
TalK to Me French Auralog. |
 |
| Reseþas Tell Me More French: |
| TELL ME MORE Homeschool Demo |
|
El reconocimiento de la gama de productos Tell Me More es razonablemente bueno (WALTJIE 2002), aunque no dejan de producirse errores y alineamientos incorrectos, debidos muchas veces a las diferencias de velocidad de elocuciµn entre el modelo y el usuario (REESER 2001, ZAHRA-ZAHRA 2005, MIURA 1997, ZHENG 2002).
La evaluaciµn automÃtica de la pronunciaciµn tiene dos objetivos principales:
Los aspectos que se suelen tener en cuenta en estos sistemas pueden ser segmentales, suprasegmentales y de fluidez. El procedimiento general se muestra en el siguiente esquema de LLISTERRI (2006), adaptado de WITT-YOUNG (2000):

LLISTERRI explica los pasos anteriores de la siguiente manera:
Veamos algunos ejemplos de estos sistemas:
| Bai&By Euskara |
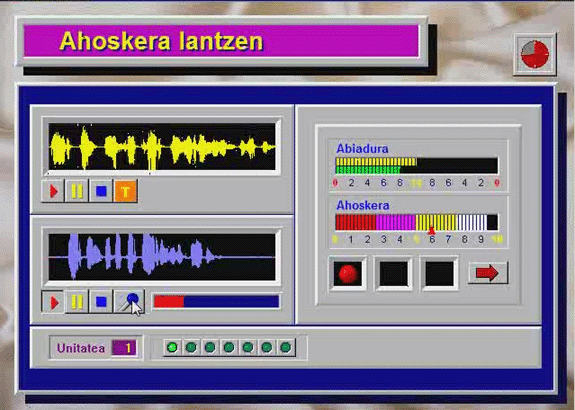 |
| Los algoritmos de reconocimiento son bastante antiguos (1999). Se està desarrollando una nueva versiµn del producto, con la colaboraciµn de Aholab. |
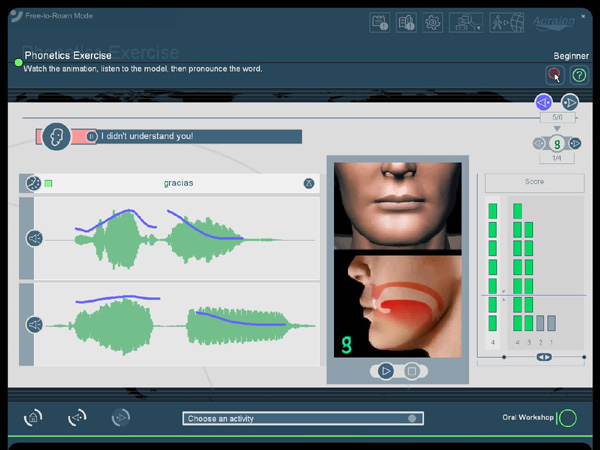
| Tell Me More Spanish |
 |
|
| Presenta una grÃfica de puntuaciµn, junto a otro tipo de informaciones ya seþaladas. |
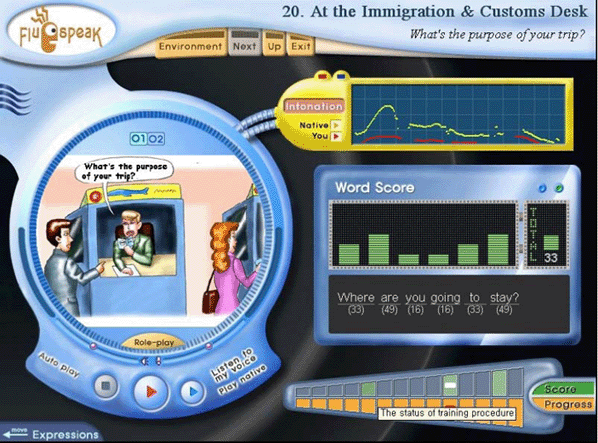
| FluSpeak |
 |
|
| FluSpeak evalºa la pronunciaciµn de cada palabra y del enunciado completo. Evalºa la prosodia y tambiÕn determinados segmentos. |
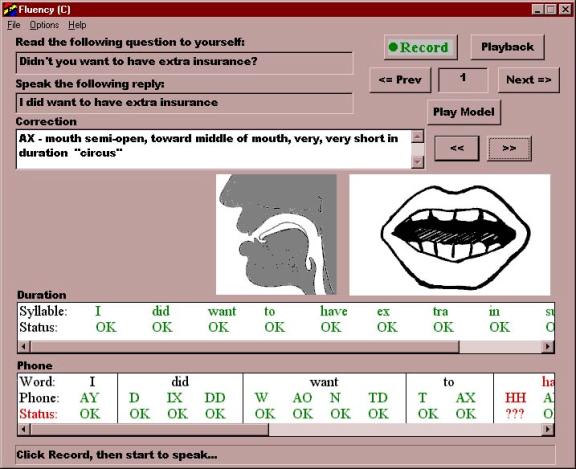
| Fluency |
 |
| Reseþas: |
| Fluency evalºa cada segmento y ofrece algunas pautas para una posible mejora en la pronunciaciµn. |
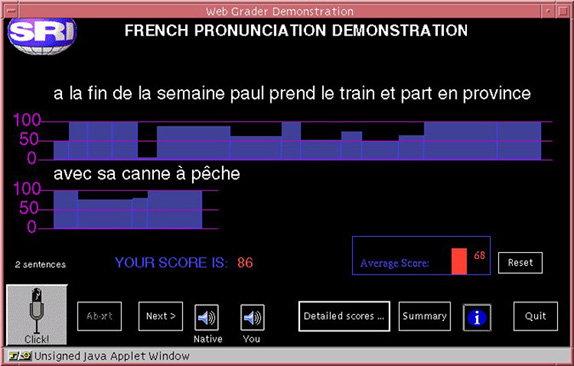
| WebGrader |
 |
|
| WebGrader realiza una valoraciµn global de la pronunciaciµn vÚa web. |
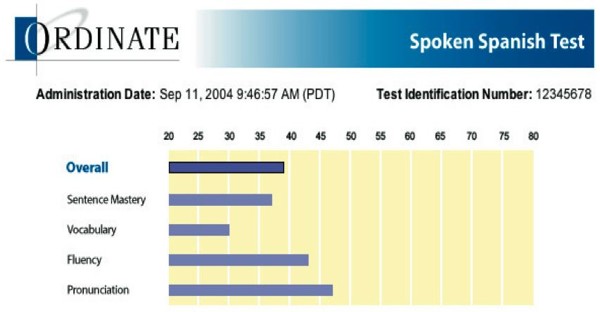
| Phone Pass Test (Ordinate) |
 |
|
| Evalºa cuatro aspectos de la destreza oral, mÃs una evaluaciµn general, todo ello por telÕfono. |
| EyeSpeak |
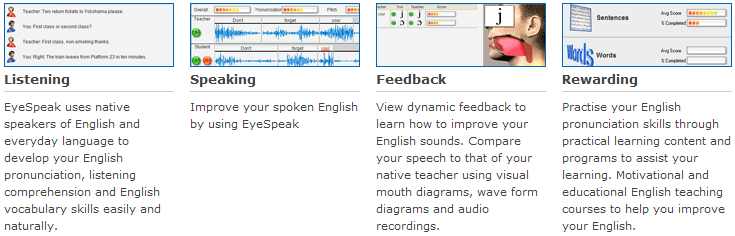 |
| Incorpora informaciµn articulatoria bastante sofisticada, al menos aparentemente. |
| ACTIVIDAD |
| Examinar los sistemas seþalados. Leer las respectivas reseþas. |
| Discutir en comºn acerca de sus caracterÚsticas, ventajas e inconvenientes. |
Como en el apartado anterior, no son muchos los estudios experimentales que evalºan estos sistemas:
TambiÕn pueden encontrarse reflexiones de tipo mÃs general sobre la utilizaciµn del RAH (ASR) en los sistemas de APAO:
| ACTIVIDAD |
| Repasar la bibliografÚa seþalada. |
| Localizar otros trabajos de interÕs. |
| Discutir en comºn acerca de la informaciµn conseguida. |
Desde el punto de vista tecnolµgico, estos sistemas tienen aºn importantes retos que superar:
Desde un punto de vista mÃs didÃctico, estos sistemas presentan tambiÕn unas carencias bastante claras:
El conocimiento fonÕtico debe ocuparse, al menos, de enfocar mejor estas cuestiones:
El objetivo del proyecto ARTUR es mejorar el aprendizaje individual de la pronunciaciµn de L2 y de personas con discapacidad auditiva (y de pronunciaciµn).
Cuando los sistemas como los que hemos examinado proporcionan algºn tipo de resultado visual de la producciµn del sujeto, ese resultado debe ser interpretado (especialmente en el caso de los sordos). Eso puede hacerlo un profesor presencial, pero el objetivo es que lo haga el propio sistema.
ARTUR usa imÃgenes tridimensionales de la cara y de partes internas de la boca (lengua, paladar, mandÚbula) para mostrar las diferencias entre la producciµn del usuario y la correcta.
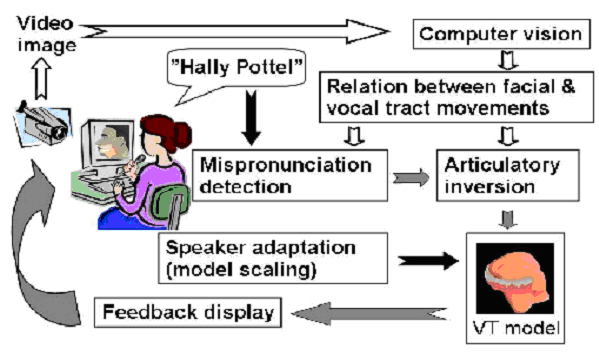
El sistema de ARTUR dispone de los siguientes mµdulos:
Informaciµn oficial:
inicio |
| Alexander Iribar >> FonÕtica >> APAO |
| Comentarios: alex.iribar@deusto.es |