Aviso: esta versión contiene algunas erratas.
[Ponencia originalmente leída en el seminario "La ingeniería lingüística en la sociedad de la información", Fundación Duques de Soria. Soria, 17-21 de julio de 2000. Posteriormente publicada en M. A. Martí y J. Llisterri.2002. Tratamiento del lenguaje natural. Edicions Universitat de Barcelona: 61-90]
Joseba Abaitua
Grupo DELi
www.deli.deusto.es
Universidad de Deusto
Los corpora bilingües son una fuente inagotable de recursos lingüísticos útiles para el desarrollo de aplicaciones como la lexicografía, la terminografía, la traducción automática, la enseñanza de segundas lenguas, la edición plurilingüe y la búsqueda translingüística de información. El avance de la tecnología de tratamiento de corpora de lengua escrita ha coincidido con el desarrollo de la tecnología web en Internet. Esta coincidencia ha propiciado una confluencia de estrategias en los dos campos, lo que se ha traducido en un interés común hacia los mecanismos de codificación y anotación, así como a la explotación de los contenidos. El plurilingüismo de Internet y los corpora multilingües son el tema principal de esta ponencia.
El año 1998, en la edición navideña de Language International 10-6, en lo que era equivalente a una carta a los Reyes Magos, Eduard Hovy, presidente de la Association for Machine Translation in the Americas (AMTA), pedía dos cosas: un gusano que recorriera Internet recogiendo los vocablos nuevos que fueran surgiendo, tanto en su versión original como en sus traducciones; y un reconocedor de géneros y de "tipos" de texto. Con ello, no sólo estaba señalando dos de los problemas más acuciantes de la tecnología del lenguaje, la diversidad lingüística y la dispersión documental, sino que además anticipaba cuál iba a ser el principal campo de aplicación: Internet.
Una de las líneas de trabajo más productivas en el contexto actual de la ingeniería lingüísitca es el tratamiento de corpora multilingües. La importancia de esta línea de trabajo está refrendada precisamente por el papel que ha adquirido Internet como vehículo de comunicación y depósito de información a escala planetaria. La red se ha convertido en el primer destinatario de aplicaciones lingüísticas, a la vez que en la más importante fuente de recursos. Es por ello que muchos estudiosos del lenguaje contemplan Internet como un inmenso corpus de información lingüística.
El primer apartado de la ponencia está dedicado a la lingüística de corpus, que es el área de la lingüística especializada en el aprovechamiento de los corpora. El segundo apartado presentará los corpora bilingües y multilingües, carcterísticas, variedades y las razones por las que se cotizan al alza (utilizaremos indistintamente los términos "multilingüe" y "plurilingüe"). El tercer apartado aborda las técnicas de tratamiento. El cuarto expone los tipos de anotaciones. El quinto y sexto se dedican a las tareas de segmentación y de alineación. De las aplicaciones se habla en el sépimo y por último se aportan algunos datos que ilustrarán la importancia del plurilingüismo en Internet.
Como paso previo a la discusión sobre los corpora multilingües, en este apartado se va a reseñar brevemente el enfoque metodológico de la lingüística de corpus. Las obras de McEnery y Wilson 1996, o Pérez Guerra 1998 son dos introducciones muy recomendables para el lector que desee ampliar conocimientos.
Los primeros estudios basados en corpus se remontan a los años del estructuralismo prechomskyano, que consideraba el acopio de datos una tarea esencial del análisis lingüístico. Suele citarse la gramática de Fries 1952 como ejemplo pionero de aprovechameinto de datos extraídos de textos reales, con un adelanto de más de treinta años sobre la obra A comprehensive grammar of the English language (de Quirk y otros, 1985). Pero la revolución del generativismo, a finales de los cincuenta, hizo que objetivos y metodologías del estructuralismo se cuestionaran. Chomsky identificó las limitaciones del corpus para explicar el carácter productivo del lenguaje y propició un cambio radical en la forma de estudiar la gramática. La lingüística abandonó los métodos empiristas basados en la observación de los datos, para promover la prospección introspectiva. Durante las décadas de los sesenta y setenta, la escuela generativa ha protagonizado la escena lingüística, desplazando los trabajos de la lingüística de corpus a un segundo plano.
Sin embargo, a finales de los ochenta algunos teóricos comenzaron a alzar la voz alertando de las limitaciones de los modelos racionalistas. Birdsong 1989, por ejemplo, cuestionó las deficiencias de algunos análisis gramáticales basados únicamente en intuiciones, a menudo imprecisas y mal contrastadas, con perjuicio de los datos empíricos observados en textos reales. Pero es sobre todo en áreas aplicadas, como la lingüística computacional, donde, pese al éxito en el desarrollo de modelos formales útiles para tratar computacionalmente muchos aspectos del lenguaje, comienzan a notarse las limitaciones del enfoque racionalista.
Los formalismos gramaticales de los ochenta (FUG, LFG, HPSG, etc.) basan su potencial en información de tipo simbólico, y carecen de capacidad para expresar datos relacionados con la frecuencia o la probabilidad. Pese a algunos intentos para combinar ambos tipos de información, los resultados han tenido poca difusión fuera del laboratorio. Entre tanto la industria necesita aplicaciones para textos reales, y eso requiere el desarrollo de gramáticas muy complejas. La enorme cantidad de variantes oracionales y sintagmáticas del lenguaje escrito es un escollo que complica esta tarea. Muchos sistemas acaban acumulando un número excesivo de reglas, lo que irremediablemente conduce a la redundacia, a la explosión combinatoria (de opciones alternativas -con devastadores efectos sobre la resolución de ambigüedades-), así como a la aparición de inconsistencias y contradicciones. Otra fuente de preocupación ha sido el reducido tamaño de los diccionarios en la mayoría de los sistemas desarrollados y la baja cobertura de texto real que ello implica.
Movidos por estas inquietudes, desde mediados de los ochenta distintos colectivos han decidido recopilar y preparar para su aplicación colecciones de corpora. Con ellos se pretende conocer mejor la realidad de los textos que se van a tratar. Merecen ser destacadas las siguientes iniciativas:
La utilidad de los corpora depende de los criterios que se aplican en el momento de selección y compilación de los textos. Varios autores (Atkins y otros 1992, Biber 1993, o McEnery y Wilson 1996) subrayan la influencia que estos criterios van a tener sobre el corpus resultante. Los corpora pueden ser de tipos muy variados. Una primera clasificación depende de la propia naturaleza física de los datos. Marcos Marín 1994 distingue tres clases:
Cada una de estas clases cumple funciones distintas y requiere por ello de tecnologías muy diferentes para su aprovechamiento. Aquí vamos a abordar la problemática de los corpora multilingües en la variedad de lengua escrita, que es la más habitual.
Otro criterio de clasificación tiene que ver con el género y la tipología textual. Este criterio afecta fundamentalmente a las propiedades de representatividad del corpus. Los criterios de selección serán muy diferenets según se pretenda diseñar un corpus especializado, como el Aarhus Corpus -sobre derecho contractual europeo-, o se desee crear un corpus de referencia, con una cobertura amplia de estilos y registros. Por definición, los corpora de referencia abarcan, de la manera más exhaustiva posible, todos los aspectos relevantes sobre una lengua. Es el caso notorio del British National Corpus (BNC), que sobrepasa los 100 millones de palabras (90% de lengua escrita y 10% de lengua hablada).
Es fácil confundir nociones como "dominio de especialidad", "campo temático", "categoría textual" o "género". Todas tienen que ver con grupos textuales que el compilador de un corpus debe considerar. Biber y Finegan 1986 y también Nakamura 1991 aplican la noción de género para distinguir los textos por su función pragmática: novela, artículo periodístico, ensayo, etc., es decir, atendiendo a factores extralingüísitcos. La noción de "tipo" de texto la emplean para distinguir los textos según las propiedades lingüísticas relacionadas con aspectos cuantitativos: longitud de oraciones, utilización de perífrasis verbales, densidad léxica, uso de conectores, etc. Laviosa 1998, por ejemplo, ha encontrado diferencias cuantitativas importantes entre textos traducidos y originales en un corpus de inglés. La tabla 1 muestra los criterios recomendados para el diseño del cropus de referencia del español, según la información proporcionada por Marcos Marín 1999 (y se comparan con los resultados del subcorpus elaborado en Argentina).
| Porcentaje recomendado en % | Género | C. argentino % |
| 10-15 | Científico | 16,11 |
| 8-12 | Comercial | 3,25 |
| 15-20 | Escolar | 9,20 |
| 5-6 | Humanísitco | 21,66 |
| 5-6 | Jurídico | 6,30 |
| 5-10 | Literario | 9,09 |
| 20-25 | Periodístico | 28,00 |
| 5-6 | Publicitario | - |
| 10-15 | Técnico | 6,79 |
| nº de palabras del corpus argentino: 2.008.969 | ||
| Tabla 1 Porcentaje de textos según géneros para corpus de referencia |
||
De los corpora de lengua española, destacan los de la Real Academia de la Lengua (RAE), ocupada desde 1995 en compilar y anotar un corpus de carácter histórico y otro de referencia del español actual:
Cada corpus contiene 125 millones de palabras, e intenta representar todos los territorios de habla hispana, tanto peninsulares como extrapeninsulares. A estos dos proyectos hay que sumar lógicamente algunos más, pero a partir de ahora vamos a centrarnos en los corpora multilingües.
Además de la RAE, varias editoriales disponen también de corpora de español: Vox Bibliograf posee uno de 10 millones de palabras, la editorial SGEL otro de 8 millones (denominado CUMBRE, Sánchez y Cantos 1997) y la editorial SM otro de 60.000 palabras (Pérez Hernández y otros 1999). En Cataluña , el Institut d'Estudis Catalans, así como TERMCAT y l'Institut Universitari de Lingüística Aplicada (IULA) de la Universitat Pompeu Fabra (Bach y otros 1997) han compilado corpora del catalán; en el País Vasco Euskaltzaindia y UZEI, así como las univesidades del País Vasco y Deusto, disponen de distintas colecciones en euskara; y en Galicia la Academia de la Lengua, ayudada por el Centro de Investigacións Ramón Piñeiro (Magán 1996), está estudiando el etiquetado de su propios recursos textuales. El principal objetivo de todos estos esfuerzos es su aplicación en el campo de la lexicografía y terminografía.
Con la rara excepción de Eaton 1940, la mayor parte de los corpora que se han recopilado en el mundo hasta fechas recientes han sido monolingües. Sin embargo, la apreciación de los corpora multilingües aumenta cada día, debido sobre todo a la riqueza de información y posibilidades de aprovechamiento que aportan. Es importante distinguir entre tres tipos:
Corpora de textos en distintos idiomas. Colecciones de textos en varios idiomas recopiladas con la intención de servir para estudios cuantitativos o estadísticos. Los criterios de selección pueden ser muy diversos, desde la simple disponibilidad de los textos, hasta la selección según géneros y tipos similares (pero sin llegar a ser comparables). Un ejemplo es el Multilingual Corpus de la European Corpus Initiative (D. McKelvie y H.S. Thompson, 1994).
Corpora comparables: Baker 1995 introdujo este término para corpora monolingües compuestos por textos originales en una lengua y traducciones de otros textos semejantes en la misma lengua. Martínez 1999 amplía el término a corpora multilingües que contienen textos en distintos idiomas, que sin ser traducciones, comparten similar origen, temática, extensión y número: partes meteorológicos, ofertas laborales, artículos periodísticos, etc. Es decir, que los textos no se reunen de manera arbitraria, sino que se escogen de acuerdo con unos criterios de selección comunes (Hallebeek 1999). Es el caso del Corpus Aarhus, compuesto por textos de derecho contractual en danés, francés e inglés; o también la colección bilingüe de textos chinos e ingleses que Fung 1995 utiliza para generar diccionarios bilingües.
Corpora paralelos: se aplica a corpora que contienen la misma colección de textos en más de una lengua, es decir, cuando a las versioes originales les acompañan sus traducciones. El caso óptimo de pararelismo se produce cuando las traducciones son un reflejo simétrico de la versión original. El caso más conocido es el Hansard Corpus, que son actas del parlamento canadiense publicadas en francés e inglés.
Existen otras consideraciones relacionadas con la traducción que se deben considerar. Las traducciones pueden responder a tipologías muy distintas. Así, por ejemplo, los textos del China News Service, que Xu y Tau 1999 alinearon como base de un sistema de traducción asistida, o los resúmenes en inglés y japonés del National Center for Sience Information Systems (NACSIS), que Kando y Aizawa 1998 utilizaron para probar la recuperación translingüística de información, tienen muy poco que ver con las actas en francés e inglés del Hansard. Tampoco es comparable una traducción de una novela de Agatha Christie con las traducciones que los autores hacen de su obra (como las traducciones al castellano que Pere Guinferrer hace de sus poemas en catalán, o la traducción al castellanoque Bernardo Atxaga hizo de su colección de relatos Obabakoak). Existen más de veinte versiones españolas de Romeo y Julieta, cada una con su rasgos y particularidades.
Para valorar adecuadamente los factores que afectan a la categorización de un corpus bilingüe, es pertinente considerar aspectos que han sido estudiados en traductología y que están relacionados con conceptos como status, función, o las distintas dimensiones de equivalencia. Sager 1993 ha introducido la noción de "status" para describir la dependencia del texto traducido respecto del original. Propone tres tipos:
Otro aspecto importante es la "función" del texto traducido. Según Rabadán 1994, la función la determina la intencionalidad comunicativa del traductor, quien puede actuar movido por alguno de los siguientes objetivos:
Otro factor clave en la traducción es el valor de equivalencia. Nord 1994 propone tres dimensiones de equivalencia:
Según el tipo de traducción, tendrá más sentido considerar una dimensión u otro de equivalencia. Así, en la traducción de Obabakoak de Bernardo Atxaga, tiene prioridad la equivalencia estilística frente a la semántica. Por contra, en un documento jurídico bilingüe o multilingüe, como es la Constitución española, o cualquier otra normativa europea, la correspondencia semántica deberá ser fiel, casi literal, respecto del original.
A los niveles típicos de procesamiento monolingüe (análisis morfológico, lematización, desambiguación, análisis sintáctico) se añade en los corpora multilingües un tipo de tratamiento particular mediante el que se establecen las equivalencias entre las unidades de textuales. Esta fase recibe distintos nombres: emparejamiento, correspondencia, aunque el término más utilizado es el de alineación. La alineación es el proceso que mayor valor añadido aporta a un corpus multilingüe.
La forma más común de marcar los resultados del procesamiento es mediante etiquetas (tags), códigos (codes) o anotaciones (annotations) -estos tres términos suelen utilizarse de manera indistinta. Las anotaciones suponen un mecanismo importante en el tratamiento de los corpora y, salvo para algunos estudios cuantitativos, resultan prácticamente imprescindibles.
Los corpora monolingües se han utilizado durante años como fuente de datos cuantitativos con aplicación en la lexicografía (generación de lexicones, comprobación de frecuencias, estudio de colocaciones, concordancias, etc.), en filología (verificación de la autoría de una obra, descripción del estilo, etc.), además de en otras disciplinas cercanas: lingüística cuantitativa, lingüística diacrónica, dialectología, psicolingüística, psicología social, sociolingüística, etc. (McEnery y Wilson 1996).
Podemos ilustrar brevemente la utilizadad de los datos cuantitativos con algunos resultados obtenidos por Laviosa 1998. Se trata de una comparación de textos origianles y traducciones, que pretendía identificar los hábitos de escritura de los traductores. El estudio se realizó sobre un corpus comparable en inglés, compusto de textos periodísticos y prosa narrativa con un tamaño de unos 2 millones de palabras, de los cuales la mitad eran textos originales y la otra mitad traducciones. Los datos cuantitativos mostraron que en las traducciones había una proporción menor de palabras léxicas frente a funcionales, con independencia de cuál hubiera sido la lengua de la que se había traducido. Asimismo se observaba que las 108 palabras más frecuentes, o lista nuclear (list head), se repetían más a menudo, que las palabras menos frecuentes variaban menos y que el tamaño medio de las oraciones era menor. El estudio también indicaba un uso distinto de los auxiliares. En conjunto, las traducciones mostraban un densidad léxica (Stubbs 1996) menor, es decir, una proporción de palabras funcionales muy alta en relación al total. En definitiva, los resultados de Laviosa concluían que es posible distinguir entre traducciones y originales a partir únicamente de datos cuantitativos.
Con todo, los estudios cuantitativos son más productivos si se realizan sobre corpora anotados. Algunos datos cuantitativos -como la longitud media de las oraciones- requieren de un proceso previo de segmentación/anotación. La oración como unidad ortográfica contenida entre dos signos de punto final es un concepto que se apoya en las convenciones de la escritura, que pueden variar de una lengua a otra. En árabe por ejemplo los signos de punto final se utilizan para distinguir párrafos, mientras que las oraciones se representan coordinadas mediante conjunciones. Las convenciones de escritura presentan dificultades de reconocimiento también para lenguas occidentales, como el inglés o el español, cuyas normas más simples son también ambiguas. El signo de punto final, por ejemplo, no sólo señala el espacio de la oración, sino que se utiliza también en acrónimos, cifras, iniciales, nomenclaturas, etc. Es por ello que las anotaciones resultan en la práctica imprescindibles para el aprovechamiento adecuado de los corpora.
Los datos lingüísticos inherentes a un corpus adquieren mayor valor cuando se explicitan mediante la incorporación de anotaciones metalingüísticas y extralingüísticas. Durante décadas han convivido distintos sistemas de anotación, con propiedades y fisonomías de muy diversa índole. En los noventa la situación ha ido paulatinamente regularizándose. Son conocidas, en este sentido, las recomendaciones de Leech 1993, que se resumen en estas siete máximas:
La última máxima de Leech refleja la situación anterior a la publicación de las directrices del Text Encoding Initiative (Sperberg-McQueen y Burnard 1994), que una parte mayoritaria de la comunidad lingüística ha adoptado ya como propuesta de anotación estándar. TEI ha sido respaldada por colectivos de gran peso, como son la Association for Computational Linguistics (ACL), la Association for Computers and the Humanities (ACH), la Association for Literary and Linguistic Computing (ALLC), o la Modern Languages Association (MLA). Vamos a repasar los logros más importantes de esta y otras iniciativas de normalización:
La aportación principal de estas iniciativas, más que la propia compilación de corpora, reside en la metodología que se aplica en el etiquetado. Debemos considerar tres tipos de anotaciones:
En el diseño de un corpus es importante tener registrados adecuadamente todos los datos relacionados con el origen de los textos: la lengua, la datación, el autor, la edición, el trancriptor, fecha de cada una de revisiones, el dominio al que pertenece; y cuanta otra información que pueda ayudar a catalogar el corpus: el género, el tipo, el status, la función, etc. Todos estos datos suelen agruparse en lo que se denomina "cabecera" (header) del corpus. TEI ha desarrollado varios modelos de cabeceras.
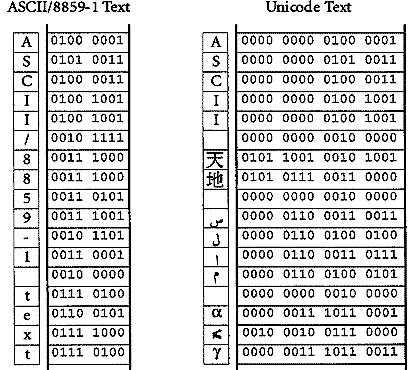
Durante algún tiempo muchos sistemas informáticos sólo
han sido capaces de tratar sistemas de escritura cuyos signos pertenecieran a
la tabla ASCII (American Standard Coding for Information Interchange),
es decir los mismos caracteres que el inglés. Si se hacían
transcripciones de otros idiomas, había que adoptar tablas de caracteres
distintas, que no eran intercambiables entre sí (como JUNET para el
japonés, o el ASCII extendido para las lenguas latinas, con versiones
incompatibles según fuera de MSDOS o Windwos). Internet ha propiciado
una vía de solución:
Los problemas relacionados con los códigos de caracteres no son exclusivos de los corpora multilingües, también puede suceder con los monolingües. El grupo ecargado del tratamiento del corpus histórico CORDE informa de problemas de segmentación, derivados de "las peculiaridades ortotipográficas, que desafían el esquema de anotación, que trata de ser respetuoso con las intervenciones de autores, copistas y editores en el texto y que, en consecuencia, dificulta las unidades de análisis lingüísitico" y las diferentes fases del etiquetado (Sánchez León 1999).
El tipo de información más valiosa de un corpus es la información de tipo lingüísitco que las anotaciones harán explícitas. Podemos considerar varios niveles:
En los siguientes apartados se van a agrupar los procesos que incorporan las anotaciones lingüísitca en el corpus en dos grupos. A la etapa propia del etiquetado monolingüe la vamos a llamar segmentación; y al proceso distintivo de los corpora multilingües, alineación.
La segmentación tiene por objetivo identificar y anotar los elementos distintivos en todos los niveles de análisis. El efecto de la segmentación se suele representar mediante etiquetas o anotaciones que se incorporan en el corpus, por lo que los tres términos a menudo se utilizan con sentido análogo. Existen varios desarrollos de segmentación morfológica, de lematización y del análisis sintáctico para el español y para el euskara. Por lo general, estos tres procesos se encadenan y simultanean con la tarea de desambiguación, es decir, de elección de la categoría más probable entre distintas opciones posibles en cada nivel. En este apartado vamos a repasar los niveles de segmentación, reseñando los trabajos que más nos pueden interesar.
En el nivel de análisis más genérico se identifican los elementos lógicos que reflejan la estructura del texto: epígrafes, apartados, párrafos, enumeraciones, oraciones, signos de puntuación, etc. Dentro de la oración se puden reconocer las palabras del léxico genérico distinguiéndolas de otros elementos como nombres propios, números, fechas, siglas, acrónimos, etc. Martínez 1999 ha desarrollado un conjunto de segmentadores modulares que añaden etiquetas estructurales de tipo SGML/TEI para el corpus bilingüe LEGEBIDUN/BOB. Estos segmentadores pueden adaptarse con facilidad a otros corpora.
Para el tratamiento morfosintáctico del español se han elaborado varios recursos. La RAE ha aplicado el generador morfológico del proyecto MULTEXT, mmorph (Bel y otros 1996). Se trata de un programa que combina morfología de dos niveles (para problemas de morfografía) y gramáticas de unificación y que reutiliza parte de los desarrollos del proyecto EUROTRA (Sánchez León 1999), los resultados se recogen en SGML/TEI (Pino y Santalla 1996). Por otro lado, en la Universidad Politécnica de Catalunya se ha desarrolado MACO+, un etiquetador basado en restricciones contextuales que resuelve mediante árboles de decisión estadísticos (Marquez y Padró 1997). Otros etiquetadores morfosintácticos para el español son SPOST (Farwell y otros 1995), SMORPH (Aït-Mokhtar y Rodrigo Mateos 1995), o el de Gala 1999. En la Universitat Pompeu Fabra se ha desarrollado CATMORF para el catalán (Badía 1997) y para el euskara, en la Universidad del País Vasco se ha desarrollado MORFEUS, un sistema que también está basado en la morfología de dos niveles (Alegria 1995 y Urkia 1997). La asignación de etiquetas morfosintácticas (etiquetas POS) suele simultanearse con la lematización.
Lematizar es reducir las formas flexivas de un texto a sus lexemas respectivos, es decir, a la forma de citación que se utiliza en los diccionarios (infinitivo para las formas verbales, masculino singular para las forma nominales). Así, tras la lematización, las formas soy, era, fui o seré serán reducidas al lexema ser. El conjunto de todas las variantes flexivas de un lexema es lo que se conoce como "lema". La lematización es importante porque permite conocer con mayor exactitud la composición léxica de los textos, y tiene especial relevancia para aplicaciones como la categorización textual o la recuperación de información. Para el español se han publicado resultados de varios lematizadores, siendo los más conocidos los de Sánchez-León 1995, Márquez y Padró 1997, o Gala 1999. Todos ellos realizan la lematización dentro del proceso de etiquetado morfosintáctico. En la Universidad del País Vasco se ha desarrollado el lematizador EUSLEM para euskara (Aduriz y otros 1996).
| forma flexiva | lexema | etiqueta POS | entidad SGML |
| que | que | PR3CN00 | que&pr3cn; |
| agota | agotar | VMIP3S0 | agota&vmip3s; |
| la | la | TFFS0 | la&tffs; |
| vía | vía | NCFS00 | vía&ncfs; |
| administrativa | administrativo | AQ0FS00 | administrativo&aq0fs; |
| podrá | poder | VMIF3S0 | podrá&vmif3s; |
| interponerse | interponer | VMN000 | interponerse&vmn; |
| recurso | recurso | NCMS00 | recurso&ncms; |
| contencioso | contencioso | AQ00000 | contencioso&aq0; |
| ante | ante | SPS00 | ante&sps; |
| Tabla 2. Resultados del lematizador de Márquez y Padró, con muestras de etiquetas morfosintácitcas (según los códigos propuestos por PAROLE) | |||
Para resolver la ambigüedad entre varias categorías candidatas existen tanto métodos de base estadística, como de base simbólica. Por los resultados obtenidos en algunas comparativas (Chanod y Tapanainen 1995) se deduce que los sistemas estadísticos tienen un comportamiento aceptable cuando el corpus es homogéneo, pero son problemáticos si no lo es. Por lo general, resulta más sencillo entrenar un desambiguador estadístico que elaborar uno simbólico. La compilación de reglas gramaticales para desambiguar es un proceso manual, particularmente largo y costoso, pero que da mejores resultados a largo plazo. El grupo de la RAE (Sánchez León 1999) ha desarrollado una herramientas de desambigüación basada en la gramática de restricciones (Constraint Grammar, Karlsson y otros 1995). El grupo IXA de la Universidad del País Vasco también ha utilizado este método, aunque lo ha combinado con otros programas de base estadística, para aprovechar las ventajas de ambas estrategias (Aduriz y otros 1999, Gojenola 2000). Marquez y Padró 1997, por su parte, resuelven la ambigüedad mediante árboles de decisión estadísticos. La desambiguación de las categorías léxicas favorece considerablemente la eficacia del análisis sintáctico.
Después de segmentar el texto en oraciones y anotar las palabras mediante etiquetas POS, el siguiente paso es reconocer las categorías sintagmáticas intraoracionales: sintagmas nominales, verbales, adjetivos, preposicionales, cláusulas subordinadas, etc. Para este proceso hacen falta analizadores sintácticos robustos, capaces de abordar cualquier tipo de construcción. Los modelos de gramáticas formales que se desarrollaron en la década de los ochenta están en su mayoría basados en reglas independientes de contexto. Tinen la ventaja de ofrecer mayor poder expresivo, pero a costa de una mayor complejidad computacional. Desde hace algunos años, para el análisis sintáctico de textos reales se ha optado por el diseño más simple de modelos basados en reglas de estados finitos. El procesamiento suele acometerse por segmentos menores a la oración, a los que se asignan categorías parciales. Es lo que se conoce como análisis superficial (shallow parsing).
Gala clasifica los analizadores superficiales en dos tipos:
Para el español se han elaborado dos analizadores superficiales: TACAT, de Atserias y otros 1998, e IFSP (Incremental Finite-State Parsing) de Gala 1999. TACAT está basado en charts con una metodología incremental que utiliza gramáticas independientes de contexto en lugar de reglas de estados finitos.
Por otro lado, IFSP aplica un efoque construccionista por medio de análisis parciales en tres fases (tabla 3):
| Fase 1: etiquetado morfosintáctico | Fase 2: etiquetado funcional | Fase 3: relaciones de dependencia |
| [SC [NP La^el+DETSG posicion^posicion+NOUNSG NP]/N [PP del^de=el+PREPDET Gobierno^gobierno+NOUNSG PP] [AP frances^frances+ADJSG AP] : v ha^haber+HAB sido^ser+PAPUX interpretada^interpretarPAPSG SC] como^como+COMO [NP una^un+DETQUANTSG manera^manera+NOUNSG NP]/N [IV de^de+PREP_DE eludir^eludir+VERBINF IV] [NP el^el+DETSG problema^problema+NOUNSG NP]/N .^.+SENT | [SC [NP El^el+DETSG problema^problema+NOUNSG NP]/SUBJ : v tiene^tener+VERBFIN SC] [NP una^un+DETQUANTSG dimension^dimension+NOUNSG NP]/OBJ [AP mayor^mayor+ADJSG AP].^.+SENT | [SC [NP Las relaciones NP]/SUBJ [AP sociales AP] :
v son SC] [AP muy informales AP], [PP en el sentido PP] [SC [PP de que PP] [NP
las personas NP]/SUBJ :v se visitan SC] [PP sin previo aviso PP] ; SUBJ(relación,ser) SUBREFLEX(persona,visitar) ATTR(relación informal) VMODOBJ(ser,en,sentido) PADJ(relación,social) ADJ(previo aviso) |
| La posición del gobierno francés ha sido interpretada como una manera de eludir el problema. | El problema tiene una dimensión mayor. | Las relaciones sociales son muy informales, en el sentido de que las personas se visitan sin previo aviso; |
| Tabla 3. Fases del etiquetador IFSP de Gala 1999. | ||
Para euskara se ha utilizado el enfoque reduccionista de la gramática de restricciones de Karlsson (Aduriz y otros 1999, Gojenola 2000, Arriola 2000). No conocemos de momento ninguna evaluación que permita comparar el rendimiento de estas tres estrategias.
El proceso que más valor añade a un corpus multilingüe es la alineación. Alinear es hacer explícitas las relaciones de correspondencia entre segmentos de una y otra lengua. La alineación no depende obligatoriamente del resto de los procesos de etiquetado, aunque una segmentación básica previa será siempre necesaria. Según Martínez 1999, existen tres enfoques principales:
Las técnicas probabilísticas que se basan en anotaciones sintácticas requieren textos etiquetados de antemano (Black y otros 1993). El Corpus Brown o el Penn Treebank (Marcos y Santorini 1991) pueden servir de modelo para el inglés. Para otras lenguas también se conocen corpora con etiquetas sintácticas: en turco (Skut y otros 1997), en checo (Hajic y Hladká 1998), en alemán (Oflazer y otros 1999). En euskara se han etiquetado sintácticamente 10.000 palabras (Ezeiza y otros 1998). Estos procesos son muy costosos, algunas métricas (Voutilainen 1997) han concluido que es necesario el trabajo de una persona entrenada durante un año para etiquetar sintácticamente un corpus de 200.000 palabras.
Martínez 1998 y 1999 obtiene muy buenos resultados sobre un corpus bilingüe en español y euskara (tabla 4) que no dispone de etiquetas sintácticas, aplicando técnicas que aprovechan las etiquetas estructurales introducidas en el proceso de segmentación monolingüe.
Foru Agindua |
Orden Foral |
| Foru Agindua, 767/1994 zk., urriaren 24ko. Aipatutako Foru Aginduaren bidez hurrengo hau xedatu da: Lurzoru batzuk dentsitate txikiko lurzoru urbanizagai gisa birsailkatzeko Zallako Udalerriko Planeamenduari buruzko Sorospidezko Arauen aldarazpena ukatzea. Erabaki honen aurka, haren jakinarazpenetik zenbatu beharreko hilabete biko epearen barruan, administraziozko liskarrauzi-errekurtsoa jarri ahal izango da, Euskal Herriko Justizia Auzitegi Nagusiko Administraziozko Liskarrauzietarako Salan, komeniesten diren beste defentsabideak erabil daitezkeelako kalterik gabe. Adierazi den epearen barruan, BHI-015/94-P05-A espedientea Bilbaoko Gran Vía, 19-21eko 5gn. solairuan egongo da ageriko, azter dadin. Bilbon, 1994.eko urriaren 24an.-Hirigintzako foru diputatua. Pedro Hernández González. |
Orden Foral número 767/1994 de 24 octubre. Mediante la Orden Foral de referencia se ha dispuesto lo siguiente: Denegar la Modificación de las Normas Subsidiarias de Planeamiento del municipio de Zalla para la reclasificación de unos terrenos como Suelo Apto para Urbanizar de Baja Densidad. Contra dicha Orden Foral podrá interponerse, en el plazo de dos meses desde su notificación, recurso contencioso-administrativo ante la Sala de lo Contencioso-Administrativo del Tribunal Superior de Justicia del País Vasco, sin perjuicio de la utilización de otros medios de defensa que estime conveniente. Durante el referido plazo el expediente BHI-015/94-P05-A, quedará de manifiesto para su examen en las dependencias situadas en Bilbao calle Alameda Rekalde, 30, 5.a y 6.a plantas. Bilbao, 24 de octubre de 1994.-El Diputado Foral de Urbanismo.- Pedro Hernández González. |
| Tabla 4. Muestra del corpus paralelo LEGEBIDUN/BOB |
|
Como resultado de la segmentación monolingüe Martínez 1998, 1999 identifica y categoriza unidades textuales -nombres propios, fórmulas y términos (tabla 5)- sobre los que posteriormente aplica técnicas de alineación.
| <rs type=organization>Euskal Herriko Justizia Auzitegi Nagusiko Administraziozko Liskarrauzietarako Salan</rs> | <rs type=organization>Sala de lo Contencioso-Administrativo del Tribunal Superior de Justicia del País Vasco</rs> |
| <rs type=law>Zallako Udalerriko Planeamenduari buruzko Sorospidezko Arauen aldarazpena</rs> | <rs type=law>Modificación de las Normas Subsidiarias de Planeamiento del municipio de Zalla </rs> |
| <term>Lurzoru batzuk dentsitate txikiko lurzoru urbanizagai gisa birsailkatzeko</term> | <term>para la reclasificación de unos terrenos como Suelo Apto para Urbanizar de Baja Densidad</term> |
| <seg type=9>Erabaki honen aurka, haren jakinarazpenetik zenbatu beharreko hilabete biko epearen barruan, administraziozko liskarrauzi-errekurtsoa jarri ahal izango da, Euskal Herriko Justizia Auzitegi Nagusiko Administraziozko Liskarrauzietarako Salan, komeniesten diren beste defentsabideak erabil daitezkeelako kalterik gabe. Adierazi den epearen barruan, BHI-015/94-P05-A espedientea Bilbaoko Gran Vía, 19-21eko 5gn. solairuan egongo da ageriko, azter dadin. Bilbon, 1994.eko urriaren 24an.-Hirigintzako foru diputatua. Pedro Hernández González. </seg> |
<seg type=9>Contra dicha Orden Foral podrá interponerse, en el plazo de dos meses desde su notificación, recurso contencioso-administrativo ante la Sala de lo Contencioso-Administrativo del Tribunal Superior de Justicia del País Vasco, sin perjuicio de la utilización de otros medios de defensa que estime conveniente. Durante el referido plazo el expediente BHI-015/94-P05-A, quedará de manifiesto para su examen en las dependencias situadas en Bilbao calle Alameda Rekalde, 30, 5.a y 6.a plantas. Bilbao, 24 de octubre de 1994.-El Diputado Foral de Urbanismo.- Pedro Hernández González. </seg> |
| Tabla 5. Segmentación en unidades de traducción. |
|
Como consecuencia de los procesos de segmentación y alineación, el corpus se enriquece con etiquetas que hacen explícita las relaciones de correspondencia entre las dos versiones. Un corpus etiquetado y alineado en todos los niveles de análisis es un recurso lingüístico de extraordinario valor (Abaitua y otros 1998).
| <div>... <seg type=9 id=9EU2 corresp=9ES2> <p id=pEU11> <s id=sEU11 corresp=ES11> <rs type=law id=LEU10 corresp=LES12>Foru agindu </rs> horrek amaiera eman dio administrazio bideari; eta beraren aurka <rs type=organization id=OEU10> Administrazioarekiko </rs> auzibide-errekurtsoa jarri ahal izango zaio <rs type=organization id=OEU11 corresp=OES9> Euskal Herriko Justizi Auzitegi Nagusiko Administrazioarekiko Auzibideetarako Salari </rs>, bi hilabeteko epean; jakinarazpen hau egiten den egunaren biharamunetik zenbatuko da epe hori; hala eta guztiz ere, egokiesten diren beste defentsabideak ere erabil litezke. </s> </p> </seg> <seg type=10 id=10EU1 corresp=10ES1> <p id=pEU12> <s id=sEU12 corresp=ES12> Epe hori amaitu arte BHI-<num num=10094> 100/94 </num>-P05-A espedientea agerian egongo da, nahi duenak azter dezan, <rs type=place id=PEU2 corresp=PES3> Bilboko Errekalde zumarkaleko </rs> <num num=30> 30.eko </num> bulegoetan, <num num=5> 5 </num> eta <num num=6> 6.</num> solairuetan.</s> </p> </seg> </div> <closer id=pEU13> <docAuthor> <s id=sEU13 corresp=ES13> <rs type=title id=TLEU4 corresp=TLES4> Hirigintzako foru diputatua </rs>. </s> <s id=sEU14 corresp=ES14> _ <rs type=name id=NEU4 corresp=NES4> Pedro Hernández González </rs>.</s> </docAuthor> | <div> ... <seg type=9 id=9ES2 corresp=9EU2> <p id=pES11> <s id=sES11 corresp=EU11> Contra dicha <rs type=law id=LES12 corresp=LEU10> Orden Foral </rs>, que agota la vía administrativa podrá interponerse recurso contencioso-administrativo ante la <rs type=organization id=OES9 corresp=OEU11> Sala de lo Contencioso-Administrativo del Tribunal Superior de Justicia del País Vasco </rs>, en el plazo de dos meses, contado desde el día siguiente a esta notificación sin perjuicio de la utilización de otros medios de defensa que estime oportunos.</s> </p> </seg> <seg type=10 id=10ES1 corresp=10EU1> <p id=pES12> <s id=sES12 corresp=EU12> Durante el referido plazo el expediente BHI-<num num=10094> 100/94 </num>- P05-A quedará de manifiesto para su exámen en las dependencias de <rs type=place id=PES3 corresp=PEU2> Bilbao calle Alameda Rekalde </rs>, <num num=30> 30 </num>, <num num=5> 5.a </num> y <num num=6> 6.a </num> plantas. </s> </p> </seg> </div> <closer=pES13> <docAuthor> <s id=sES13 corresp=EU13> El <rs type=title id=TLES4 corresp=TLEU4> Diputado Foral de Urbanismo </rs>. </s> <s id=sES14 corresp=EU14> - <rs type=name id=NES4 corresp=NEU4> Pedro Hernández González </rs> </s> </docAuthor> </closer> |
| Tabla 6. Muestra de sección del corpus alineada (Martínez 1999) |
|
Durante la década de los noventa, la alineación de corpora ha sido una de las líneas de actuación más esperanzadoras de la ingeniería lingüística. Gale y Church 1991, Dagan y otros 1993, Macklovitch 1994, McEnery y Oakes 1996, Schmied y Schäffler 1996, o Melamed 1997, son otras referencias destacables.
A principios de la década de los noventa, los campos de la lexicografía y terminografía, así como la traducción automática protagonizaron la actividad en torno a los corpora multilingües. En la actualidad el interés se ha ampliado hacia otras áreas como la enseñanza de segundas lenguas o la didáctica de la traducción, herederas de experiencias muy anteriores (McEnery y Wilson 1996). Pero las dos apliciones que más atención recaban en estos momentos son la recuperación translingüísitica de información y la internacionalización de productos.
Una aplicación tradicional de los corpora multilingües es en la enseñanza de segundas lenguas. Como actividad más reciente vamos a destacar el International Corpus of Learner English (ICLE) de la Universidad de Lovaina-la Neuve. Este corpus contiene una colección de composiciones cortas hechas por estudiantes de niveles altos de inglés de procedencia dispar: chinos, checos, holandeses, finlandeses, franceses, alemanes, japoneses, polacos, rusos, españoles y suecos. El objetivo de esta recopilación es comprobar la hipótesis del "modelo de lengua común" al que se llega en los niveles avanzados. Se ha comprobado, por ejemplo, que los alumnos abusan de ciertas palabras (verbos auxiliares, pronombres personales, algunas conjunciones, como and y but, los verbos get y think, algunas palabras de significado vago, como people, things, del cuantificador very) y que infrautilizan otras (como the, this, these, o by). También se ha estudiado la influencia de las respectivas lenguas maternas sobre el modelo de adquisición de la segunda lengua.
Cuando una palabra se infrautiliza a menudo indica que se produce un alerta inconsciente ante un problema de aprendizaje. Así en el corpus alemán, el verbo become se utiliza mucho menos que en los otros corpora, porque tiene un falso amigo en bekommen, palabra muy frecuente en alemán que tiene un significado muy distinto del inglés. Los estudiantes tienden a evitar palabras que perciben como potencialmente conflictivas y tienden a utilizar el léxico que les es más familiar. Esta actitud ha sido muy estudiada y se denomina "principio del oso de peluche", teddy bear principle.
Baker 1996 y 1997 ha defendido la utilidad de los corpora comparables para estudiar la traducción, sobre todo en su aplicación a la enseñanza. Han comprobado que factores extralingüísticos, como el sexo del traductor, su edad, la lengua de origen, etc. influyen sobre las traducciones. Atendiendo a la propuesta de Toury 1995, el grupo de Baker (Laviosa 1997 y 1998, Sardinha 1997) pretende descubrir las "leyes probabilísticas y condicionales del comportamiento traduccional" (laws of translational behaviour), a partir de los datos de un extenso corpus comparable de textos originales y traducciones.
Con fines análogos se han realizado estudios contrastivos el inglés y el sueco (Johansson. 1996), así como entre el inglés y el noruego (Johansson y Ebeling 1996), o el inglés y el polaco (Piotrowska 1997). Otro corpus diseñado para servir de modelo en la didáctica de la traducción es el Corpus LSP, del Institut Universitari de Lingüística Aplicadade la Universitat Pompeu Fabra (Vivaldi 1996, Bach y otros 1997).
Los lexicógrafos siempre han recurrido a grandes colecciones de textos para desarrollar su trabajo de creación y actualización de diccioarios. Este trabajo ha sido tradicionalmente lento y laborioso. Por ello se ha recibido con júbilo la disponibilidad de corpora en formato electrónico, así como las técnicas y herramientas que hacen posible su procesamiento (Pérez Hernández y otros 1999). La Real Academia de la Lengua ha comenzado a basar sus trabajos lexicográficos en los corpora CORDE y CREA (Sánchez-León 1999). Pero, además de la RAE, varias editoras de diccionarios de español también disponen de corpora: Vox Bibliograf posee uno de 10 millones de palabras, la editorial SGEL uno de 8 (corpus CUMBRE, Sánchez y Cantos 1997) y SM otro de 60.000 palabras (Pérez Hernández y otros 1999). En Cataluña , el Institut d'Estudis Catalans, así como TERMCAT e IULA; en el País Vasco Euskaltzaindia y UZEI, en Galicia la Academia de la Lengua, así como el Centro de Investigacións Ramón Piñeiro (Magán 1996), realizan todos ellos labores de lexicografía y terminografía sobre la base de datos obtenidos de corpora.
Si los corpora monolingües contribuyen sustancialmente en el desarrollo de diccionarios monolingües, no menos útiles son los corpora multilingües (Álvarez 1999). Numerosos autores han contribuido en los últimos años a la creación y enriquecimiento de diccionarios y tesauros bilingües aprovechando los datos disponibles en corpora: Gale y Church 1991; Daille y otros 1994; Catizone y otros 1993; Kumano y Hirakawa 1994; Klavans y Tzoukermann 1995, Langlois 1996. Aplicando similares técnicas a textos de especialidad ha sido posible extraer glosarios terminológicos, o identificar términos compuestas y construcciones colocacionales: Eijk 1993; Kupiec 1993; Dagan y Church 1994; Samajda y otros 1996; Resnik y Melamed 1997.
Por otro lado, los trabajos de Briscoe y Carroll 1997, o Lapta 1999, han abierto nuevas vías de investigación en la lexicografía computacional al haber ensayado la extracción automática de patrones de subcategorización verbal a partir de corpora. Arriola 2000 ha realizado un experimento similar para euskara.
La disponibilidad del Hansard Corpus en formato electrónico despertó el interés de los investigadores del Watson Centre de la IBM (Brown y otros 1990) que lo aprovecharon para ensayar métodos alternativos de traducción automática. Los métodos basados en reglas (conocidos por el acrónimo inglés RBMT, Rule-based Machine Translation) habían llegado a finales de los ochenta a un punto de estancamiento y la comunidad investigadora comenzaba a buscar nuevos enfoques. Es el retorno de los métodos empíricos que ya habían sido probados en los albores de la disciplina (Weaver 1949) . El cambio de enfoque en los noventa se ve favorecido por el drástico abaratamiento de los micoroprocesadores y las unidades de almacenamiento. Con ello comienzan a proliferar las colecciones de textos en formato electrónico y su disponibilidad favorecida por Internet es una invitación a probar los métodos probabilísticos y conexionistas, que tan buenos resultados habían dado ya en el tratamiento de corpora orales. El número de sistemas diseñados se multiplica (Catizone y otros 1993, Kay y Röscheisen 1993; Vogel y otros 1996, Wu 1996 y Tillmann y otros 1997), de forma que puede decirse que el paradigma de la traducción por reglas ha perdido numerosos adeptos en beneficio de la traducción por analogías, ABMT, Analogy-based Machine Translation (Jones 1992).
Nagao 1984 ya había anticipado este cambio con su propuesta de traducción basada en ejemplos (EBMT, Example-based Machine Translation), técnica que ha tenido gran eco en la comunidad científica. Sadler 1989 se sirvió de un corpus alineado para crear una base de ejemplos bilingües, utilizada luego como recurso de traducción automática. Tsuji y otros 1991 y Sumita e Iida 1991 aplican enfoques híbridos. La traducción basada en ejemplos ha tenido su mayor aplicación en una tecnología conocida como "memoria de traducción" (MBMT, Memory-based Machine Translation). Consiste en el almacenamiento de traducciones realizadas manualmente y validadas por el traductor, de forma que puedan ser reutilizadas posteriormente para textos similares que se reconocen mediante umbrales de similitud basados generalmente en lógica difusa. Esta tecnología ha sido llevada al mercado con un considerable éxito: Déjà-Vu (ATRIL), Translator's Workbench (TRADOS), Transit (STAR), SDLX, son algunas de las herramientas de mayor difusión.
Un enfoque alternativo a la traducción automática es la generación de textos multilingües (Kittredge 1989, Hartley y Paris 1997). Movidos por el éxito de los sistemas de escritura asistida por ordenador (Gómez Guinovart 1999, Gojenola y Oronoz 2000), varios proyectos han probado a simultanerar los procesos de composición y traducción. Esta técnica ha resultado muy adecuada para textos cuyo esquema se ciñe a un guión prestablecido y recurrente. A partir de una muestra representativa de partes meteorológicos en varios idiomas, Chevreau y otros 1999 han desarrollado MultiMétéo, un sistema que permite generar automáticamente partes mulitlingües. Otro sistema de este tipo es TREE, que genera ofertas de empleo multilingües (Somers 1992). En nuestro entorno más cercano se debe reseñar GIST, proyecto europeo para la generación plurilingüe de textos instructivos (Lavid 1995 y 1996), así como LEGEBIDUN ( Abaitua y otros 1997, Casillas y otros 1999, 2000). A partir de un corpus paralelo alineado de documentos administrativos en euskara y castellano, Casillas 2000 ha diseñado un generador de nuevos documentos bilingües.
Pero el sector de mayor crecimiento es la internacionalización de productos. Desde hace poco más de un lustro, la edición en CD-ROM, la producción de páginas web y, sobre todo, la industria de software han hecho que el enfoque de la traducción cambie radicalmente. La necesidad de actualizar cíclicamente los productos y su distribución en los mercados internacionales obliga a las empresas a realizar importantes esfuerzos para satisfacer las exigencias lingüísticas y culturales de esos mercados. Microsoft, por ejemplo, adapta a más de 25 idiomas sus principales productos, y tiene muy buenos motivos para hacerlo así. Según datos publicados por la propia empresa (Brooks 2000), más de la mitad de sus ingresos proceden del comercio exterior (unos 5.000 millones de dólares).
La adaptación de un programa de software no es un mero problema de traducción. Hay muchos factores que deben estar previstos en la propia fase de diseño. Además de traducir los títulos, los mensajes, las ayudas on-line, o los menús que interactúan con el usuario, para adaptar un programa de sofware hay que resolver otros aspectos que son difíciles de notar a simple vista. El cambio de alfabeto es una fuente obvia de dificultades, pero los problemas más delicados son los que tienen que ver con el código del programa. La traducción de las llamadas a función de los menús, por ejemplo, puede afectar al tamaño de los registros, o al código de las instrucciones que los ejecutan. Los enlaces de Internet, el tratamiento de cifras y fechas también deberán ser adaptado. Si el programa además dispone de herramientas de tratamiento propiamente lingüístico -relacionadas con los formatos, la corrección ortográfica, gramatical o de estilo, los diccionarios y glosarios- el proceso se complicará considerablemente.
La adaptación lingüística y cultural de sofware se conoce como "localización" (calco directo del término anglosajón localisation) y forma parte de lo que en el contexto empresarial se relaciona con la "internacionalización" de un producto. Es una actividad que está en expansión y que ha generado un importante nicho de mercado. Si se menciona aquí es porque la tecnología que se utiliza en la localización está relacionada con la lingüística de corpus. En el sector aeronáutico, por ejemplo, la documentación de cualquier producto ocupa considerable espacio y se distribuye en formato electrónico, generalmente en CD-ROM. Estos manuales y libros de referencia, cuando se traducen, se convierten en genuinos corpora bilingües. Para su traducción y actualización se utilizan los gestores de memorias de traducción.
Las redes internacionales y la difusión de bases documentales hace cada vez más relevante la cuestión del acceso y recuperación multilingüe de la información. Los proyectos de digitalización de bibliotecas que se iniciaron primero en países de habla inglesa, se han extendido ya a todas las regiones del mundo. Tanto Asia como Europa están experimentando un rápido desarrollo de sus infraestructuras para la distribución de sus fondos documentales, lo que significa que materiales en multitud de idiomas han comenzado a ser accesibles por red.
Unido al crecimiento de bibliotecas digitales monolingües en distintos idiomas, existen también bibliotecas multilingües en países con más de una lengua nacional, o en países donde el inglés es la legua usada para la documentación técnica o científica, en instituciones paneuropeas o en empresas transnacionales. Todo esto ha despertado la conciencia de que deben diseñarse herramientas con capacidad translingüística para la recuperación y extracción de información. Es una de las áreas de investigación que ha experimentado mayor crecimiento en ingeniería lingüística y en apenas unos años los foros, reuniones internacionales, así como las publicaciones han experimentado un auge espectacular. Estas son algunas referencias obligadas: Oard y Dorr 1996, Sheridan y Ballerini 1996, Picchi y Peters 1996, Gilarranza, Gonzalo y Verdejo 1997, Kando y Aizawa 1998, Grefenstette 1998, o Pazienza 1999; sobre bibliotecas digitales, Peters y Picchi 1997; sobre técnicas de categorización de documentos, Yang 1998.
Internet se ha convertido en el pricipal campo de aplicación de las técnicas de tratamiento de corpora multilingües. Pese a un acusado desequilibrio inicial favorable al inglés, la tendencia actual es hacia la correción de la balanza lingüísitca. En la medida en que la situación se vaya normalizando, aumentará la información en idiomas distintos del inglés, como cabe prever de la comparación del porcentaje de páginas web con el de publicaciones o traducciones en formato tradicional (Lockwood 1998). En la actualidad la proporción de páginas web en inglés casi triplica al de publicaciones en papel. Para otras lenguas con presencia internacional, sólo el japonés mantiene una relación equitativa entre lo que se publica en web y en papel. La desproporción es acusada para el resto, y particularmente grave en el caso del chino.
| lenguas | en las que se publica | a las que se traduce | páginas web (UL) | páginas web (IC) | pag./hab. |
| inglés | 28% | 5% | 75% | 70,05% | (81,51) |
| chino | 13% | 0,5% | - | 0,71% | 0,86 |
| alemán | 12% | 17% | 4,02% | 3,34% | 51,77 |
| francés | 8% | 6% | 2,81% | 1,96% | 23,26 |
| español | 7% | 16% | 2,53% | 1,51% | 22,94 |
| japonés | 5% | 5% | - | 5,01% | (69,96) |
| ruso | 5% | 3% | - | - | |
| portugués | 5% | 0% | 0,82% | 0,73% | (7,51) |
| neerlandés | 2% | 7% | - | 0,71% | 56,85 |
| otras | 15% | 41% | 14,82% | 15.98% | |
| 100% | 100% | 100% | 100% | ||
| Tabla 7. Comparativa de presencia internacional de las principales lenguas | |||||
Unión Latina (UL) publicó en 1998 una encuesta basada en consultas para 57 palabras (del tipo a "ambigüedad" o "rodilla") entre los principales buscadores de Internet. En 1999 se publicó una segunda encuesta realizada por Pedro Maestre para el Instituto Cervantes (IC), sobre los 180 millones de páginas indizadas en Altavista Magallanes. Los resultados de ambas encuestas se parecen y dan unas tasas de presencia similares. El español ocupa en ambos casos el quinto lugar, con 2,6 millones de páginas según el cálculo de Maestre, de las que más de la tercera parte corresponden a España. Se sitúa muy cerca del francés, pero bastante por debajo del japonés y el alemán. El inglés exhibe una supremaciá absoluta, con índices entre el 70 y el 75%. La ubicuidad de la red y la condición del inglés como lingua franca son los dos factores a los que se atribuye esta desproporción. Un dato ilustrativo de la encuesta de Masetre es la significativa presencia de lenguas pequeñas como el neerlandés. Su presencia cuantitativa, en número de páginas, es equiparable a la del chino, con una tasa de páginas por habitante que resulta ser 657,18 veces más alta que la tasa de páginas en chino.( Los datos de la última columna de la tabla 7 corresponden a la proporción de páginas por cada 1.000 habitantes en los países de origien -España, Francia etc.- y se han extraído de la encuesta de Maestre, salvo las cifras entre paréntises, que se han calculado sobre el total de hablantes, y no sobre el de habitantes).
De lo que no disponemos es de datos sobre la presencia de páginas bilingües o multilingües en la red, aunque hay claros indicios de su rápido crecimiento. Una parte importante de las publicaciones en Internet proviene de los medios de comunicación, de las empresas transnacionales y de las instituciones internacionales. Todos ellos se afanan para que sus presencia en la red supere las barreras lingüísitcas. Por ello, pese a la supremacía de los textos monolingües, la red se ha convertido también en un vasto corpus multilingüe que crece exponencialmente. Esto ha disparado la demanda de tecnologías con capacidad de procesamiento multilingüe: buscadores inteligentes, sistemas de indización y catalogación, extractores de información, gestores de conocimientos, generadores de textos, generadores de resúmenes, etc. La lingüística de corpus y las técnicas de alineación tienen el campo abonado en Internet.