Language Engineering
Harnessing the Power of Language
Language EngineeringHarnessing the Power of Language |
|
The use of language is currently restricted. In the main, it is only used in direct communications between human beings and not in our interactions with the systems, services and appliances which we use every day of our lives. Even between humans, understanding is usually limited to those groups who share a common language. In this respect language can sometimes be seen as much a barrier to communication as an aid.
A change is taking place which will revolutionise our use of language and greatly enhance the value of language in every aspect of communication. This change is the result of developments in Language Engineering.
Language Engineering provides ways in which we can extend and improve our use of language to make it a more effective tool. It is based on a vast amount of knowledge about language and the way it works, which has been accumulated through research. It uses language resources, such as electronic dictionaries and grammars, terminology banks and corpora, which have been developed over time. The research tells us what we need to know about language and develops the techniques needed to understand and manipulate it. The resources represent the knowledge base needed to recognise, validate, understand, and manipulate language using the power of computers. By applying this knowledge of language we can develop new ways to help solve problems across the political, social, and economic spectrum.
Language Engineering is a technology which uses our knowledge of language to enhance our application of computer systems:
New opportunities are becoming available to change the way we do many things, to make them easier and more effective by exploiting our developing knowledge of language.
When, in addition to accepting typed input, a machine can recognise written natural language and speech, in a variety of languages, we shall all have easier access to the benefits of a wide range of information and communications services, as well as the facility to carry out business transactions remotely, over the telephone or other telematics services.
When a machine understands human language, translates between different languages, and generates speech as well as printed output, we shall have available an enormously powerful tool to help us in many areas of our lives.
When a machine can help us quickly to understand each other better, this will enable us to co-operate and collaborate more effectively both in business and in government.
The success of Language Engineering will be the achievement of all these possibilities. Already some of these things can be done, although they need to be developed further. The pace of advance is accelerating and we shall see many achievements over the next few years.
For each one of us, our own language is fundamental to our national and cultural identity, providing a link to our traditions as well as the foundation of our education and entertainment.
In Europe we have the benefit of a diversity of languages and cultures, which means that we have the opportunity to learn a great deal about each others' culture and way of life. This remains one of the bases for a cohesive European society. If the benefits of a multi-lingual society are to remain a feature of the European way of life then we must explore ways in which to overcome the barriers to communication and understanding.
It is sometimes said that it is possible to use only one or two languages for international activities in business, administration and politics. To a certain extent this is true. However, it could never be entirely satisfactory. The dominance of a few languages would be an unacceptable imbalance of power as well as a poor use of resources.
Above all, it reduces significantly the number of people who can participate effectively in any activity and this is bound to exclude valuable contributions and lead to discontent. In time, such an approach would also marginalise the languages which are not used so widely, reducing further the scope of their usage and inevitably diminishing the richness and variety of our culture. It would adversely affect not only our feeling for national, regional and cultural identities, but also our sense of belonging to a truly European society, not just tolerant of its minorities but supportive of them, recognising their value.
Such a restrictive approach to language use would also limit the availability of a wide range of important new services and facilities by denying many people access to computer systems in their native language.
Europe's position as a naturally multi-lingual community in a multi-lingual world can be used to our commercial advantage. As we endeavour to collaborate more closely, to develop the single market as our home market, we have a special incentive to develop solutions to the problems of a multi-lingual market place. In successfully supporting our own language needs, especially in business, administration and education, Language Engineering will help us to compete for business in the global marketplace. On the one hand, our businesses will have a competitive edge through their experience in using technology to service the needs of a multi-lingual marketplace. On the other hand, we shall also have language products to sell to the rest of the world.
A pattern of life-long learning is expected to be one of the significant features of the Information Society. It is also recognised that managers of the future will need to be capable in more than one language. Language Engineering will make an important contribution to the development of personal tuition systems, not only for language learning but also in developing systems which adapt more effectively to the needs of the student.
Language enabled products will improve the performance of business and administration as well as individuals. Products which are developed using language technology will revolutionise our systems and enhance the range of services available to business, government and the public at large.
Speech recognition, understanding, and generation by computer, will make human computer interaction more efficient as well as more human. Natural language understanding by machines, will deliver our information needs with more precision and sensitivity, helping us to overcome the problem of having too much information to cope with.
Computer aided translation services and the generation of documents in foreign languages will not only improve our dealings within Europe but will also help to give us greater access to external markets.
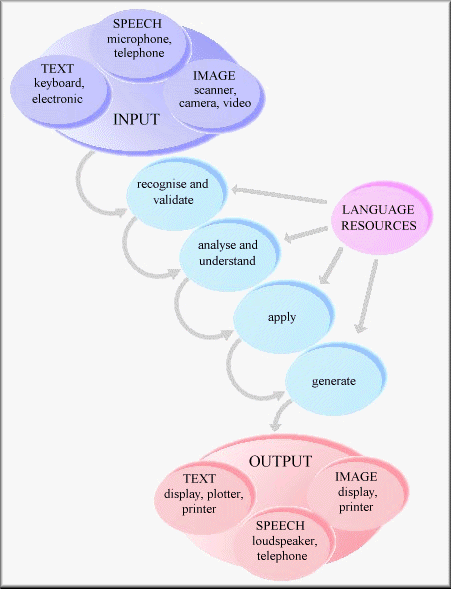
Model of a Language Enabled System
Within this general model there are, of course, many different configurations. Depending on the application of the technology, not all these components are needed.
There are a number of significant problems to be overcome if speech is to become a commonly used medium for dealing with a computer. The first of these is the ability to recognise continuous speech rather than speech which is deliberately delivered by the speaker as a series of discrete words separated by a pause. The next is to recognise any speaker, avoiding the need to train the system to recognise the speech of a particular individual. There is also the serious problem of the noise which can interfere with recognition, either from the environment in which the speaker uses the system or through noise introduced by the transmission medium, the telephone line, for example. Noise reduction, signal enhancement and key word spotting can be used to allow accurate and robust recognition in noisy environments or over telecommunication networks. Finally, there is the problem of dealing with accents, dialects, and language spoken, as it often is, ungrammatically.
OCR from a single printed font family can achieve a very high degree of accuracy. Problems arise when the font is unknown or very decorative, or when the quality of the print is poor. In these difficult cases, and in the case of handwriting, good results can only be achieved by using ICR. This involves word recognition techniques which use language models, such as lexicons or statistical information about word sequences.
Document image analysis is closely associated with character recognition but involves the analysis of the document to determine firstly its make-up in terms of graphics, photographs, separating lines and text, and then the structure of the text to identify headings, sub-headings, captions etc. in order to be able to process the text effectively.
Shallow or partial analysis of texts is used to obtain a robust initial classification of unrestricted texts efficiently. This initial analysis can then be used, for example, to focus on 'interesting' parts of a text for a deeper semantic analysis which determines the content of the text within a limited domain. It can also be used, in conjunction with statistical and linguistic knowledge, to identify linguistic features of unknown words automatically, which can then be added to the system's knowledge.
Semantic models are used to represent the meaning of language in terms of concepts and relationships between them. A semantic model can be used, for example, to map an information request to an underlying meaning which is independent of the actual terminology or language in which the query was expressed. This supports multi-lingual access to information without a need to be familiar with the actual terminology or structuring used to index the information.
Combinations of analysis and generation with a semantic model allow texts to be translated. At the current stage of development, applications where this can be achieved need be limited in vocabulary and concepts so that adequate Language Engineering resources can be applied. Templates for document structure, as well as common phrases with variable parts, can be used to aid generation of a high quality text.
Dialogue can be established by combining speech recognition with simple generation, either from concatenation of stored human speech components or synthesising speech using rules.
Providing a library of speech recognisers and generators, together with a graphical tool for structuring their application, allows someone who is neither a speech expert nor a computer programmer to design a structured dialogue which can be used, for example, in automated handling of telephone calls.
The work of producing and maintaining language resources is a huge task. Resources are produced, according to standard formats and protocols to enable access, in many EU languages, by research laboratories and public institutions. Many of these resources are being made available through the European Language Resources Association (ELRA).
Proper names: Dictionaries of proper names are essential to effective understanding of language, at least so that they can be recognised within their context as places, objects, or person, or maybe animals. They take on a special significance in many applications, however, where the name is key to the application such as in a voice operated navigation system, a holiday reservations system, or railway timetable information system, based on automated telephone call handling.
Terminology: In today's complex technological environment there are a host of terminologies which need to be recorded, structured and made available for language enhanced applications. Many of the most cost-effective applications of Language Engineering, such as multi-lingual technical document management and machine translation, depend on the availability of the appropriate terminology banks.
Wordnets: A wordnet describes the relationships between words; for example, synonyms, antonyms, collective nouns, and so on. These can be invaluable in such applications as information retrieval, translator workbenches and intelligent office automation facilities for authoring.
There are national corpora of hundreds of millions of words but there are also corpora which are constructed for particular purposes. For example, a corpus could comprise recordings of car drivers speaking to a simulation of a control system, which recognises spoken commands, which is then used to help establish the user requirements for a voice operated control system for the market.

Model of Language Engineering Activities
In practice, Language Engineering is applied at two levels. At the first level there are a number of generic classes of application, such as:
At the second level, these enabling applications are applied to real world problems across the social and economic spectrum. So, for example:
In general, language capability is embedded in systems to enhance their performance. Language Engineering is an 'enabling technology'.
Information is available throughout the world, on the World Wide Web, for example, in different languages. In reality, however, it is only available to a client who can firstly request the information in the language in which it is recorded and then understand the language in which the information is presented. Using machine translation facilities the person seeking information will be able to complete an information request in his or her native language and receive the information in that same language, regardless of the language in which the information is recorded.
Language Engineering can improve the quality of information services by using techniques which not only give more accurate results to search requests, but also increase greatly the possibility of finding all the relevant information available. Use of techniques like concept searches, i.e. using a semantic analysis of the search criteria and matching them against a semantic analysis of the database, give far better results than simple keyword searches.
One of the major, direct benefits of the Information Society for the ordinary citizen will be the improvement in public service information. However, the wide accessibility of this information will depend upon Language Engineering. People who are not familiar with the conventional user interface of a computer system will be able to request information by voice and the system will guide them through the possibilities. Those who want information about other countries, which may be held in a foreign language, will be able to receive it in their own language. A good example of this is a service which is currently being developed which will provide information about job opportunities across the European Union in the native language of the potential applicant. Obviously these are jobs where language skills are not significant. The service will be available on the Internet and it is also planned to have public booths where job seekers can use the service. In a mono-lingual pilot service run in Flanders, a surprising 26% of applications for jobs were received from applicants who had seen the details on the Internet.
Language Engineering will make a contribution in a large number of public interest areas. Intelligence gathering for law enforcement is an interesting case. In detecting smuggling for example, there is a large amount of information available from public or commercial sources which, if collated and presented in the right way, can give clear indications of suspicious activity. Details about ship movements, manifests and company information can highlight abnormal profiles of activity. The ability of language based analysis to produce these profiles is an important aid.
Apart from the economic advantage of automating services to provide 'around the clock' availability, it also removes the need for people to work long and unsociable hours to provide the necessary coverage. Services are likely to be more consistent, fast, and reliable. In addition the automatic recording of an audit trail for each transaction will mean that each party to the transaction can feel confident about its outcome.
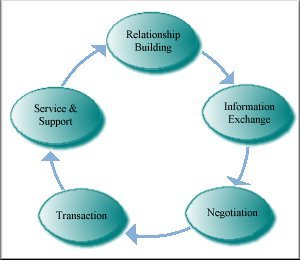
The Cycle of Commerce
To the human user one of the advantages of the World Wide Web is that information is published in natural language. However, for a software agent to scan and select information from the Web, requires that it is given the intelligence to understand the published information and match it to the requirements of its user. Language Engineering can make a significant contribution to the development of intelligent agents which can undertake to provide consumers with an easy way of using the facilities of electronic commerce. A consumer could instruct such an agent, by voice, to browse the Web or any similar service, to read catalogues and select suitable products, to look for and negotiate prices, even assemble bids in an electronic auction. When the results have been reviewed the consumer would then tell the agent to place the order and, subsequent to delivery, instruct the bank to pay an electronic invoice. The human users would see none of the complexity of the underlying commercial transactions which would be dealt with by the agent.
After sales service can also be improved by using hypertext based electronic help desks with additional, language enabled facilities. The benefits of this automation are immense. Apart from the reduction of costs throughout the business transaction cycle, a wider choice of suppliers and products can be reviewed and assessed for suitability, and competitive pricing will be stimulated. The whole process will be faster and more efficient and, once the relevant information has been recorded, the accuracy of all the derivative processes can be assured.
In time, electronic commerce will change the business model itself. There will be less need for middlemen. New and small enterprises will be able to make the world aware of their products and services quickly, effectively and without too much expense. However, without language understanding and multi-lingual capability, these benefits cannot be fully realised.
As the application of language knowledge enables better support for translators, with electronic dictionaries, thesauri, and other language resources, and eventually when high quality machine translation becomes a reality, so the barriers will be lowered. Agreements at all levels, whether political or commercial, will be better drafted more quickly in a variety of languages. International working will become more effective with a far wider range of individuals able to contribute. An example of a project which is successfully helping to improve communications in Europe is one which interconnects many of the police forces of northern Europe using a limited, controlled language which can be automatically translated, in real-time. Such a facility not only helps in preventing and detecting international crime, but also assists the emergency services to communicate effectively during a major incident.
A good example of the type of service which will be available is an automated legal advice service. The accessibility of the justice system to all citizens is becoming a serious problem in many societies where the cost of legal expertise and the process of law prevents all but the very rich, and those qualifying for legal aid, from exercising their legal rights. It will be possible using language based techniques not only to provide advice which is based on an understanding of the problem and an analysis of the relevant body of law, but also to understand a natural language description of the problem and deliver the advice, as a human lawyer would have done, in spoken or printed form. Such a service could be made available through kiosks in court buildings or post offices, for example. This type of application can also be used to inform citizens of social security entitlements and job opportunities, as well as providing a useable, comprehensible interface to more open government.
Systems with the capacity to communicate with their users interactively, through human language, available either through access points in public places or in the home, via the telephone network or TV cables, will make it possible to change the nature of our democracy. There will be a potential for participation in the decision-making process through a far greater availability of information in understandable and 'objective' form and through opinion gathering on a very large scale. Many people whose lives are affected by disability can be helped through the application of language technology. Computers with an understanding of language, able to listen, see and speak, will offer new opportunities to access services at home and participate in the workplace.
In future, in Europe, it will be essential in many walks of life to be competent in more than one language. Of course, computer aided language learning (CALL) is an area of prime importance for the application of Language Engineering. The same knowledge that is essential to the machine's ability to understand, is also the basis for the interactive teaching process, providing quality diagnostics of student errors as well as illustrating correct usage. New, more effective learning facilities at home and at work will greatly increase the opportunities to expand our knowledge and develop new skills.
For a wider range of people, writing can become a more exciting activity. Authoring tools will make it possible for them to achieve much higher quality results. The use of on-line dictionaries and thesauri, for example, makes selection of the 'mot juste' more likely, and grammar can be checked. The result can be a far more satisfying experience for writers who are not naturally gifted or well educated but who want to express themselves effectively in their business or social correspondence.
| abstract | [n] | a short, concise description of a document, which covers the full scope of its contents |
| ambiguity | [n] | a state whereby a word or sentence can be understood in different ways; the former because the word has more than one meaning or the latter because the structure of the sentence can be analysed in such a way as to convey more than one meaning |
| authoring tools | [p] | facilities provided in conjunction with word processing to aid the author of documents, typically including an on-line dictionary and thesaurus, spell-, grammar-, and style-checking, and facilities for structuring, integrating and linking documents |
| CALL | [a] | Computer Aided Language Learning |
| character recognition | [p] | see Character and Document Recognition |
| computational linguistics | [p] | an area of applied linguistics concerned with the processing of natural language by computers |
| concept search | [p] | used in the context of information retrieval to mean that the search is made using a semantic analysis of the search filter matched against a semantic analysis of the database |
| continuous speech | [p] | speech where the speaker makes no allowances for the listener (e.g. a speech recognition device) by pausing between words |
| controlled language | [p] | language which has been designed to restrict the number of words and the structure of (also artificial language) language used, in order to make language processing easier; typical users of controlled language work in an area where precision of language and speed of response is critical, such as the police and emergency services, aircraft pilots, air traffic control, etc. |
| corpus (plural corpora) | [n] | see Corpora |
| dialogue | [n] | an interactive, two way alternate flow of language between two individuals, an individual and a machine, or between two machines |
| dictionary | [n] | a list of words and a description of each, usually confined to describing their meaning and possibly their etymology |
| discourse | [n] | a contiguous stretch of language comprising more than one sentence |
| discourse analysis | [p] | analysis to identify the linguistic dependencies which exist between sentences |
| document image recognition | [p] | see Character and Document Image Recognition |
| domain | [n] | usually applied to the area of application of the language enabled software e.g. banking, insurance, travel, etc.; the significance in Language Engineering is that the vocabulary of an application is restricted so the language resource requirements are effectively limited by limiting the domain of application |
| formalism | [n] | a means to represent the rules used in the establishment of a model of linguistic knowledge |
| generate | [v] | to produce language in one form from another form of language or information see also Speech Generation and Natural Language Generation |
| globalisation | [n] | the process of preparing software for use in any language and cultural environment either by designing it to be usable in this way or by adding facilities to existing software to facilitate subsequent localisation (see below) |
| grammar | [n] | see Grammars |
| grammar checker | [p] | a software facility which checks text for the correctness of its grammar |
| hidden Markov model | [p] | a finite state machine in which not only transitions are probabilistic but also output; currently used in speech recognition systems to help to determine the words represented by the sound wave forms captured |
| hypertext | [n] | a system commonly used for help files and in the World Wide Web whereby highlighted text is used to provide a link (rather like an index) to related text (often a more detailed explanation of the item highlighted) |
| index | [v] | to build a concise means of reference to information within a database which, for textual information, can be based on keywords or concepts |
| information extraction | [p] | the process of selecting information from a database using indices based on keywords, semantics, and/or concept searching |
| information retrieval | [p] | usually used as a generic term to cover the access to and delivery of information from natural language databases by whatever method |
| interlingua | [n] | an invented language which can be used as a common, formal representation into which source natural language may be translated and from which target natural language can be generated |
| interpret | [v] | generally, to attribute meaning to language; but also, to translate from one language to another, usually orally, in real-time |
| language enabled | [p] | describes a computer application which has been improved in functionality, performance, enhanced and/or presentation by the use of language engineering |
| language engineering | [p] | the application of knowledge of language to the development of computer systems which can recognise, understand, interpret and generate human language in all its forms |
| language resources | [p] | see Language Resources |
| lemmatise | [v] | to break an inflected word into its root (base form) and ending components |
| lexicon | [n] | see Lexicons |
| localise | [v] | to adapt software to the local requirements in terms of language and culture (including legal practice and business conventions, for example) |
| machine translation | [p] | the process of automatically translating from one language to another by a computer |
| machine aided translation | [p] | the process of assisting a human translator in translating from one language to another using computer software tools |
| machine readable | [p] | a dictionary (see above) which can be read by computer dictionary software |
| mark up | [v] | to annotate text so that its structure and presentation are defined in such a way that the structure can be reproduced by a software system other than that used for its creation |
| morpheme | [n] | the smallest meaningful element of language |
| morphology | [n] | the science of the structure of words |
| multi-lingual | [adj] | properly used to mean that something exists in a form that can handle several languages but often used to describe the characteristic that versions exist in several languages |
| natural language generation | [p] | see Natural Language Generation |
| natural language processing | [p] | a term in use since the 1980s to define a class of software systems which handle text intelligently |
| OCR | [a] | see Optical Character Recognition below |
| Optical Character Recognition | [p] | see Character and Document Image Recognition |
| onomastics | [n] | scientific investigation of proper names (see Specialist Lexicons) |
| parse | [v] | analyse language in order to establish its structure and relationships at a the level of syntax and/or semantics |
| phoneme | [n] | the smallest unit of sound (analogous to a morpheme) which can be identified from an acoustic flow of speech and which is semantically distinct |
| proper names | [p] | see Specialist Lexicons |
| semantics | [n] | the analysis of language to determine meaning |
| shallow parser | [p] | software which parses language to a point where a rudimentary level of understanding can be realised; this is often used in order to identify passages of text which can then be analysed in further depth to fulfil the particular objective |
| speaker identification | [p] | see Speaker Identification and Verification |
| speaker independent | [p] | describes a speech recognition system which is capable of recognising speech regardless of the speaker, i.e. it does not need to be trained to recognise individual speakers |
| speaker verification | [p] | see Speaker Identification and Verification |
| speech recognition | [p] | see Speech Recognition |
| speech generation | [p] | see Speech Generation |
| speech to text | [p] | the process of analysing speech and producing its textual equivalent; a typical example of a speech to text application is in dictation systems |
| spell checker | [p] | software which checks the spelling of words |
| style check | [p] | software which checks a document to ensure that it conforms to a template defining the structure of the text and the document containing it; also the checking of the use of phrases or sentences in a predefined way |
| summarise | [v] | to produce a concise description of a document, which covers the full scope of its contents |
| syllable | [n] | a unit of pronunciation which is more than a single sound (see phoneme above) and smaller than a word |
| syntax | [n] | the system of rules which describe how sentences can be formed from basic elements of language, i.e. morphemes, words and parts of speech |
| tag | [v] | to annotate a corpus by attaching information to the words, which describes the grammatical context of the words and/or associations with other words |
| terminology | [n] | see Specialist Lexicons |
| text | [n] | used frequently to distinguish written, printed, or symbolically recorded (using character encoding) language from speech |
| text alignment | [p] | the process of aligning different language versions of a text in order to be able to identify equivalent terms, phrases, or expressions |
| text to speech | [p] | the process of producing the speech equivalent of text; a typical example of a text to speech application is an automatic announcement system at an airport or railway station |
| thesaurus | [n] | a dictionary of synonyms |
| translate | [v] | to transfer a text from one language to another |
| translation memory | [p] | a system which builds knowledge about translating from one language to another by remembering and re-using previous translations |
| translator's workbench | [p] | a software system providing a working environment for a human translator, which offers a range of aids such as on-line dictionaries, thesauri, translation memories, etc |
| user modelling | [p] | usually, in dialogue based speech recognition, a component which attempts to be sensitive to the various sorts of users that the system may encounter |
| utterance | [n] | the string of sounds produced by a speaker between two pauses |
| version | [n] | an edition of a document which is recorded as different from the previous edition |
| version control | [p] | the management of the production, recording, and issue of documents |
| voice authentication | [p] | speaker verification |
| voice recognition | [p] | speech recognition |
| wizard of Oz testing | [p] | testing in which the automated machine component is substituted by some form of human intervention but in such a way that the user participating in the test is unaware of the substitution |
| wordnet | [n] | see Specialist Lexicons |